
[ad_1]
In machine learning, one method that has consistently demonstrated its worth across various applications is the Support Vector Machine (SVM). Known for its adeptness at parsing through high-dimensional spaces, SVM is designed to draw an optimal dividing line, or hyperplane, between data points belonging to different classes. This hyperplane is critical as it allows predictions about new, unseen data, emphasizing SVM’s strength in creating models that generalize well beyond the training data.
A persistent challenge within SVM approaches concerns how to handle samples that are either misclassified or lie too close to the margin, essentially, the buffer zone around the hyperplane. Traditional loss functions used in SVM, such as the hinge loss and the 0/1 loss, are pivotal for formulating the SVM optimization problem but falter when data is not linearly separable. They also exhibit a heightened sensitivity to noise and outliers within the training data, affecting the classifier’s performance and generalization to new data.
SVMs have leveraged a variety of loss functions to measure classification errors. These functions are essential in setting up the optimization problem for the SVM, directing it towards minimizing misclassifications. However, conventional loss functions have limitations. For instance, they need to penalize misclassified samples adequately or those that fall within the margin despite being correctly classified, the critical boundary that delineates classes. This shortfall can detrimentally affect the classifier’s generalization ability, rendering it less effective when exposed to new or unseen data.
A research team from Tsinghua University has introduced a Slide loss function to construct an SVM classifier. This innovative function considers the severity of misclassifications and the proximity of correctly classified samples to the decision boundary. This method, through the concept of proximal stationary point and properties of Lipschitz continuity, defines Slide loss function support vectors and a working set for (Slide loss function-SVM), along with a fast alternating direction method of multipliers (Slide loss function-ADMM) for efficient handling. By penalizing these aspects differently, the Slide loss function aims to refine the classifier’s accuracy and generalization ability.
The Slide loss function distinguishes itself by penalizing misclassified and correctly classifying samples that linger too close to the decision boundary. This nuanced penalization approach fosters a more robust and discriminative model. By doing so, the method seeks to mitigate the limitations posed by traditional loss functions, offering a path to more reliable classification even in the presence of noise and outliers.
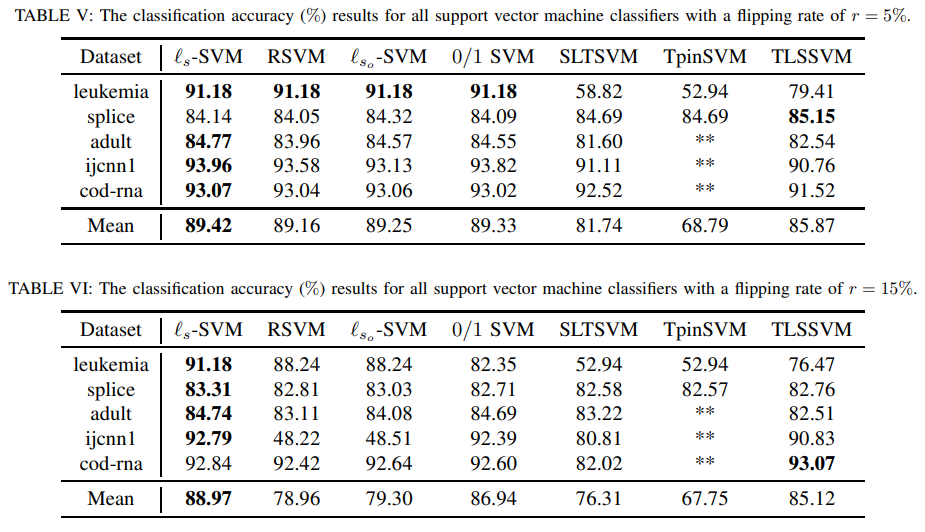
The findings were compelling for the current research: the Slide loss function SVM demonstrated a marked improvement in generalization ability and robustness compared to six other SVM solvers. It showcased superior performance in managing datasets with noise and outliers, underscoring its potential as a significant advancement in SVM classification methods.

In conclusion, the innovation of the Slide loss function SVM addresses a critical gap in the SVM methodology: the nuanced penalization of samples based on their classification accuracy and proximity to the decision boundary. This approach enhances the classifier’s robustness against noise and outliers and its generalization capacity, making it a noteworthy contribution to machine learning. By meticulously penalizing misclassified samples and those within the margin based on their confidence levels, this method opens new avenues for developing SVM classifiers that are more accurate and adaptable to diverse data scenarios.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our Telegram Channel, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 39k+ ML SubReddit
![]()
Hello, My name is Adnan Hassan. I am a consulting intern at Marktechpost and soon to be a management trainee at American Express. I am currently pursuing a dual degree at the Indian Institute of Technology, Kharagpur. I am passionate about technology and want to create new products that make a difference.
[ad_2]
Source link
Be the first to comment