
[ad_1]
The transformer model has emerged as a cornerstone technology in AI, revolutionizing tasks such as language processing and machine translation. These models allocate computational resources uniformly across input sequences, a method that, while straightforward, overlooks the nuanced variability in the computational demands of different parts of the data. This one-size-fits-all approach often leads to inefficiencies, as not all sequence segments are equally complex or require the same level of attention.
Researchers from Google DeepMind, McGill University, and Mila have introduced a groundbreaking method called Mixture-of-Depths (MoD), which diverges from the traditional uniform resource allocation model. MoD empowers transformers to dynamically distribute computational resources, focusing on the most pivotal tokens within a sequence. This method represents a paradigm shift in managing computational resources and promises substantial efficiency and performance improvements.
MoD’s innovation lies in its ability to adjust computational focus within a transformer model dynamically, applying more resources to parts of the input sequence that are deemed more critical for the task at hand. The technique operates under a fixed computational budget, strategically selecting tokens for processing based on a routing mechanism that evaluates their significance. This approach drastically reduces unnecessary computations, effectively slashing the transformer’s operational demands while maintaining or enhancing its performance.
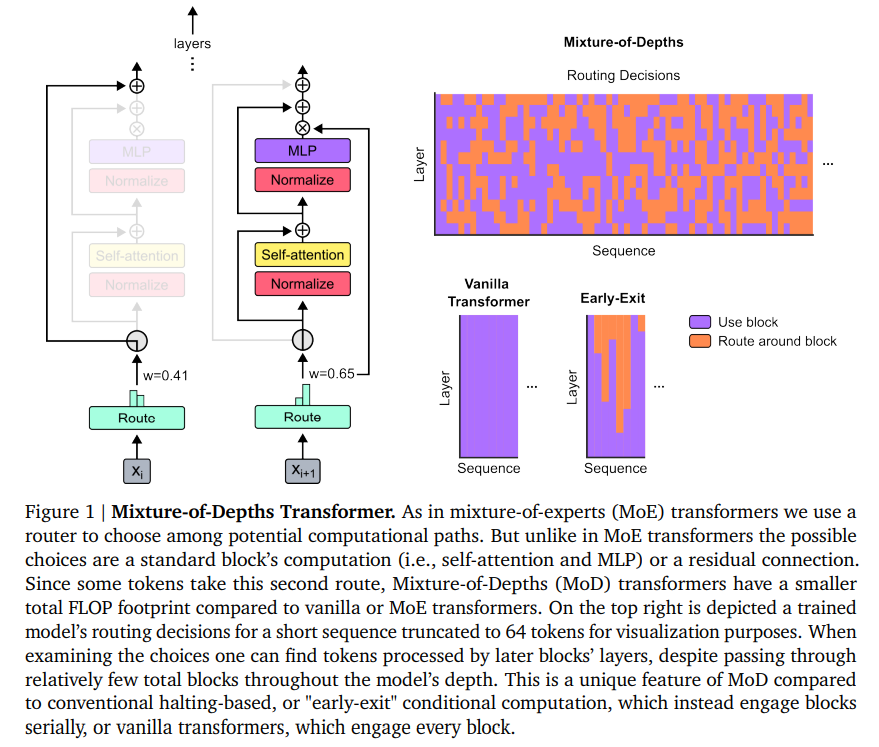
MoD-equipped models demonstrated the ability to maintain baseline performance levels with substantially reduced computational loads. For example, models could achieve training objectives with identical Flops (floating-point operations per second) to conventional transformers but required up to 50% fewer Flops per forward pass. These models could operate up to 60% faster in certain training scenarios, showcasing the method’s capability to significantly boost efficiency without compromising the quality of results.

In conclusion, the principle of dynamic compute allocation is revolutionizing efficiency, with MoD underscoring this advancement. By illustrating that not all tokens require equal computational effort, with some demanding more resources for accurate predictions, this method paves the way for significant compute savings. The MoD method presents a transformative approach to optimizing transformer models by dynamically allocating computational resources addressing inherent inefficiencies in traditional models. This breakthrough signifies a shift towards scalable, adaptive computing for LLMs.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our Telegram Channel, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 39k+ ML SubReddit
![]()
Hello, My name is Adnan Hassan. I am a consulting intern at Marktechpost and soon to be a management trainee at American Express. I am currently pursuing a dual degree at the Indian Institute of Technology, Kharagpur. I am passionate about technology and want to create new products that make a difference.
[ad_2]
Source link
Be the first to comment